
何かと便利なOCR
紙ベースの資料をスキャンして、OCRで文字認識させて全文検索に利用しようって考えは以前からあって、10年くらい前にチャレンジしたものの、実用的でなく断念したことがあります。
最近、ドキュワークスでOCR機能を使ってみたら、意外にも認識率が「使える」レベルになっていたので、スクリプトで扱えるようにして、日常業務に取り入れることにしました。
基礎資料
動作確認環境
WindowsXP
Excel 2002 SP3
Fuji Xerox DocuWorks Desk 6.2.4
Fuji Xerox DocuWorks API DLL xdwapi.dll 6.2.0.35
参考資料
DocuWorks Development Tool Kit 6.2.5 日本語版(http://www.fujixerox.co.jp/download/soft/docuworks/download301.html)
DocuWorks Development Tool Kit 7.2 日本語版(http://www.fujixerox.co.jp/product/software/docuworks/download501.html)
実際にXDWAPIを利用する際には、DocuWorks API (XDWAPI)仕様書(XDWAPI.XDW)で、詳細を確認してください。
各種定数やエラーコードなどは、XDWAPIを利用するためのヘッダファイル(xdw_api.h xdwapian.h)に記載されています。
ヘッダファイルはDocuWorks Development Tool Kitに含まれています。
サンプルスクリプト
サブプロシージャ「ApplyOcrAll」は、指定したファイルの全てのページの全体をOCR処理します。
また、サブプロシージャ「ApplyOcrParts」は、指定したファイルの指定したページの指定部分をOCR処理します。
今回提示したサンプルでは、3ページ目の左上5cmの正方形と、右上の縦5cm×横10cmの長方形部分をOCR処理します。
宣言文中のxdwapi.dllファイルのパスは、環境に合わせて修正してください。
DocuWorks API(XDWAPI)仕様書に記載があるように、 一度でもXDW_ApplyOcr関数を呼び出した場合は、アプリケーションのプロセスが終了する前にXDW_Finalizeを呼び出さなければなりません。
例えば、Excelの標準モジュールを使っていたら、Excelファイルを閉じる前に、サブプロシージャ「DoXDWFinalize」を走らせてください。
XDW_Finalize 関数を適用せずにExcelファイルを閉じると、次のような「アプリケーションエラー:メモリが”read”になることはできませんでした。プログラムを終了するには、[OK]をクリックしてください。」メッセージが表示されます。
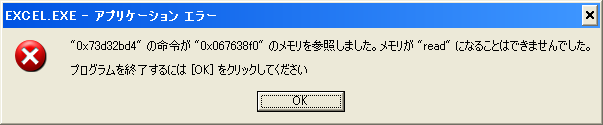
Accessでは出ないようなんですけどね。
Option Explicit
'動作環境 WindowsXP Excel2002 DocuWorks6.2
'2.20 XDW_Finalize 特定APIの終了処理を行う。
Public Declare Function XDW_Finalize Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal reserved As String) As Long
'2.3 XDW_ApplyOcr DocuWorksファイルの指定ページをOCR処理する。
Private Declare Function XDW_ApplyOcr Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal handle As Long, ByVal nPage As Long, ByVal nOcrEngine As Long, ByVal pOcrOption As Long, ByVal reserved As String) As Long
Private Type XDW_OCR_OPTION_V5_EX
nSize As Long '構造体XDW_OCR_OPTION_V5_EXのバイト数を設定する。
nNoiseReduction As Long 'ノイズ除去の強さを指定する。
nLanguage As Long '言語を指定する。
nInsertSpaceCharacter As Long '空白文字を挿入するかどうかを指定する。
nJapaneseKnowledgeProcessing As Long '日本語知識処理を行うかどうかを指定する。
nForm As Long '原稿レイアウトの構成を指定する。
nColumn As Long '原稿レイアウトの段組を指定する。
nDisplayProcess As Long '認識処理の過程を表示するかどうかを指定する。
nAutoDeskew As Long '自動的に傾き補正を行うかどうかを指定する。
nAreaNum As Long 'OCR処理する領域の個数を指定する。
pAreaRects As Long 'OCR処理する領域の座標(四角形)を指定する。
nPriority As Long 'カラーイメージ、および、グレースケールイメージに対する前処理を指定する。
End Type
'2.34 XDW_GetDocumentInformation DocuWorksファイル全体に関わる情報を得る。
Private Declare Function XDW_GetDocumentInformation Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal handle As Long, ByRef pDocumentInfo As XDW_DOCUMENT_INFO) As Long
Private Type XDW_DOCUMENT_INFO
nSize As Long '構造体XDW_DOCUMENT_INFOのバイト数を設定する。
nPages As Long '総ページ数。
nVersion As Long 'DocuWorksファイルのファイルフォーマットのバージョン。
nOriginalData As Long 'オリジナルデータの数。
nDocType As Long 'ファイルの種類。
nPermission As Long '認可情報。
nShowAnnotations As Long 'アノテーションの表示状態。
nDocuments As Long 'nDocTypeがバインダーである場合はバインダーの内部DocuWorks文書数を示す。
nBinderColor As Long 'nDocTypeがバインダーである場合はバインダーの色を示す。
nBinderSize As Long 'nDocTypeがバインダーである場合はバインダーのサイズを示す。
End Type
Private Type XDW_RECT '四角形の左上隅と右下隅の座標を定義
left As Long '四角形の左上隅の x 座標
top As Long '四角形の左上隅の y 座標
right As Long '四角形の右下隅の x 座標
bottom As Long '四角形の右下隅の y 座標
End Type
'2.6 XDW_CloseDocumentHandle DocuWorksファイルにアクセスするためのハンドルを解放する。
Private Declare Function XDW_CloseDocumentHandle Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal handle As Long, ByVal reserved As String) As Long
'2.64 XDW_OpenDocumentHandle DocuWorksファイルにアクセスするためのハンドルを得る。
Private Declare Function XDW_OpenDocumentHandle Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal lpszFilePath As String, ByRef pHandle As Long, ByRef pMode As XDW_OPEN_MODE) As Long
Private Type XDW_OPEN_MODE
nSize As Long
nOption As XDW_OPEN
End Type
'2.73 XDW_SaveDocument 変更を DocuWorks ファイルに反映させる。
Private Declare Function XDW_SaveDocument Lib "D:\dwsdk625\XDWAPI\DLL\xdwapi.dll" (ByVal handle As Long, ByVal reserved As String) As Long
Private Enum XDW_OPEN
XDW_OPEN_READONLY = 0
XDW_OPEN_UPDATE = 1
End Enum
Private Enum XDW_OCR_ENGINE 'OCRエンジンの種類
XDW_OCR_ENGINE_DEFAULT = 1 'DocuWorks付属の内蔵型OCR
XDW_OCR_ENGINE_WRP = 2 'メディアドライブ(株) WinReader PRO
End Enum
Private Enum XDW_REDUCENOISE 'ノイズ除去の強さ
XDW_REDUCENOISE_NONE = 0 'ノイズ除去を行わない (default)
XDW_REDUCENOISE_NORMAL = 1 'ふつう
XDW_REDUCENOISE_WEAK = 2 '弱く
XDW_REDUCENOISE_STRONG = 3 '強く
End Enum
Private Enum XDW_OCR_LANGUAGE '言語を指定
XDW_OCR_LANGUAGE_AUTO = -1 '自動判別 (default)
XDW_OCR_LANGUAGE_JAPANESE = 0 '日本語
XDW_OCR_LANGUAGE_ENGLISH = 1 '英語
End Enum
Private Enum XDW_OCR_FORM '原稿レイアウトの構成を指定
XDW_OCR_FORM_AUTO = 0 '自動判別 (default)
XDW_OCR_FORM_TABLE = 1 '表
XDW_OCR_FORM_WRITING = 2 '文章
End Enum
Private Enum XDW_OCR_COLUMN '原稿レイアウトの段組を指定
XDW_OCR_COLUMN_AUTO = 0 '自動判別 (default)
XDW_OCR_COLUMN_HORIZONTAL_SINGLE = 1 '横書き一段
XDW_OCR_COLUMN_HORIZONTAL_MULTI = 2 '横書き多段
XDW_OCR_COLUMN_VERTICAL_SINGLE = 3 '縦書き一段
XDW_OCR_COLUMN_VERTICAL_MULTI = 4 '縦書き多段
End Enum
Sub ApplyOcrAll()
'DocuWorksファイルをOCR処理する(全ページのページ全体)
Dim strFileName1 As String 'ファイル名
Dim PageNo As Long '処理するページ番号
'Docworksを使うための前処理(ここから)
Dim lngHandle, lngHandleAnnotation As Long
Dim myMode As XDW_OPEN_MODE
Dim myInfo As XDW_DOCUMENT_INFO
With myMode 'XDW_OpenDocumentHandleを実行する際のmyModeに値を設定
.nOption = XDW_OPEN_UPDATE
.nSize = LenB(myMode)
End With
With myInfo 'XDW_GetDocumentInformationを実行する際のmyInfoに値を設定
.nSize = LenB(myInfo)
End With
'Docworksを使うための前処理(ここまで)
strFileName1 = "D:\test001.xdw"
'DocuWorksファイルにアクセスするためのハンドルを得る。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_OpenDocumentHandle strFileName1, lngHandle, myMode
'DocuWorksファイル全体に関わる情報を得る。
XDW_GetDocumentInformation lngHandle, myInfo
'OCR処理の準備。
Dim myXDW_OCR_OPTION_V5_EX As XDW_OCR_OPTION_V5_EX
Dim myXDW_OCR_ENGINE As XDW_OCR_ENGINE
Dim myXDW_REDUCENOISE As XDW_REDUCENOISE
Dim myXDW_OCR_LANGUAGE As XDW_OCR_LANGUAGE
Dim myXDW_OCR_FORM As XDW_OCR_FORM
Dim myXDW_OCR_COLUMN As XDW_OCR_COLUMN
'変数を設定
myXDW_OCR_ENGINE = XDW_OCR_ENGINE_DEFAULT 'OCRエンジンにDocuWorks付属の内蔵型OCRを使用する。
myXDW_REDUCENOISE = XDW_REDUCENOISE_NONE
myXDW_OCR_LANGUAGE = XDW_OCR_LANGUAGE_AUTO
myXDW_OCR_FORM = XDW_OCR_FORM_AUTO
myXDW_OCR_COLUMN = XDW_OCR_COLUMN_AUTO
'XDW_OCR_OPTION_V5_EX構造体に変数を設定
With myXDW_OCR_OPTION_V5_EX
.nNoiseReduction = myXDW_REDUCENOISE
.nLanguage = myXDW_OCR_LANGUAGE
.nInsertSpaceCharacter = 0
.nJapaneseKnowledgeProcessing = 1
.nForm = myXDW_OCR_FORM
.nColumn = myXDW_OCR_COLUMN
.nDisplayProcess = 1
.nAutoDeskew = 1
.nAreaNum = 0
.nSize = LenB(myXDW_OCR_OPTION_V5_EX)
End With
PageNo = 1
Do
'DocuWorksファイルの指定ページをOCR処理する。
XDW_ApplyOcr lngHandle, PageNo, myXDW_OCR_ENGINE, VarPtr(myXDW_OCR_OPTION_V5_EX), vbNullString
PageNo = PageNo + 1
Loop Until PageNo > myInfo.nPages
'変更を DocuWorks ファイルに反映させる。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_SaveDocument lngHandle, vbNullString
'DocuWorksファイルにアクセスするためのハンドルを解放する。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_CloseDocumentHandle lngHandle, vbNullString
End Sub
Sub ApplyOcrParts()
'DocuWorksファイルをOCR処理する(指定ページの指定部分)
Dim strFileName1 As String 'ファイル名
Dim Err_XDW_ApplyOcr As String
'Docworksを使うための前処理(ここから)
Dim lngHandle, lngHandleAnnotation As Long
Dim myMode As XDW_OPEN_MODE
Dim myInfo As XDW_DOCUMENT_INFO
With myMode 'XDW_OpenDocumentHandleを実行する際のmyModeに値を設定
.nOption = XDW_OPEN_UPDATE
.nSize = LenB(myMode)
End With
With myInfo 'XDW_GetDocumentInformationを実行する際のmyInfoに値を設定
.nSize = LenB(myInfo)
End With
'Docworksを使うための前処理(ここまで)
strFileName1 = "D:\test001.xdw"
'DocuWorksファイルにアクセスするためのハンドルを得る。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_OpenDocumentHandle strFileName1, lngHandle, myMode
'DocuWorksファイル全体に関わる情報を得る。
XDW_GetDocumentInformation lngHandle, myInfo
'OCR処理の準備。
Dim myXDW_OCR_OPTION_V5_EX As XDW_OCR_OPTION_V5_EX
Dim myXDW_OCR_ENGINE As XDW_OCR_ENGINE
Dim myXDW_REDUCENOISE As XDW_REDUCENOISE
Dim myXDW_OCR_LANGUAGE As XDW_OCR_LANGUAGE
Dim myXDW_OCR_FORM As XDW_OCR_FORM
Dim myXDW_OCR_COLUMN As XDW_OCR_COLUMN
Dim myXDW_RECT(1) As XDW_RECT
'変数を設定
myXDW_OCR_ENGINE = XDW_OCR_ENGINE_DEFAULT 'OCRエンジンにDocuWorks付属の内蔵型OCRを使用する。
myXDW_REDUCENOISE = XDW_REDUCENOISE_NONE
myXDW_OCR_LANGUAGE = XDW_OCR_LANGUAGE_AUTO
myXDW_OCR_FORM = XDW_OCR_FORM_AUTO
myXDW_OCR_COLUMN = XDW_OCR_COLUMN_AUTO
With myXDW_RECT(0)
.left = 1000
.top = 1000
.right = 6000
.bottom = 6000
End With
With myXDW_RECT(1)
.left = 10000
.top = 1000
.right = 20000
.bottom = 6000
End With
'XDW_OCR_OPTION_V5_EX構造体に変数を設定
With myXDW_OCR_OPTION_V5_EX
.nNoiseReduction = myXDW_REDUCENOISE
.nLanguage = myXDW_OCR_LANGUAGE
.nInsertSpaceCharacter = 0
.nJapaneseKnowledgeProcessing = 1
.nForm = myXDW_OCR_FORM
.nColumn = myXDW_OCR_COLUMN
.nDisplayProcess = 1
.nAutoDeskew = 1
.nAreaNum = UBound(myXDW_RECT, 1) + 1
.pAreaRects = VarPtr(VarPtr(myXDW_RECT(0)))
.nSize = LenB(myXDW_OCR_OPTION_V5_EX)
End With
'DocuWorksファイルの指定ページの指定部分をOCR処理する。
Err_XDW_ApplyOcr = XDW_ApplyOcr(lngHandle, 3, myXDW_OCR_ENGINE, VarPtr(myXDW_OCR_OPTION_V5_EX), vbNullString)
'変更を DocuWorks ファイルに反映させる。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_SaveDocument lngHandle, vbNullString
'DocuWorksファイルにアクセスするためのハンドルを解放する。関数が正常に終了したら0を返す。異常終了したときは、エラーコードを返す。
XDW_CloseDocumentHandle lngHandle, vbNullString
End Sub
Sub DoXDWFinalize()
'アプリケーションを閉じるときに走らせ、XDW_RotatePageAutoのAPIで確保していたメモリーやリソースを解放する。
'特定APIの終了処理を行う。
XDW_Finalize vbNullString
End Sub
OCR処理をする関数 XDW_ApplyOcr
XDW_ApplyOcr関数の定義
XDW_ApplyOcrの定義は次のようになっています。
int XDW_ ApplyOcr (XDW_DOCUMENT_HANDLE handle, int nPage, int nOcrEngine, void* pOcrOption, void* reserved);
詳しくはXDWAPI仕様書をご覧いただくとして、第4引数のpOcrOptionにNULLを設定すると全てデフォルト値で動作します。しかし、せっかくなので構造体XDW_OCR_OPTION_V5_EXを設定して、かゆいところに手が届くようにしておきます。
制限事項
XDWAPI仕様書には、下記のように説明があります。
指定したページはイメージから作成されたページでなくてはならない。それ以外のページに対してこの関数を呼び出すと、エラーになる。
ちなみに、アプリケーションから作成されたページにOCR処理をすると、「XDW_E_INVALID_OPERATION」エラーが返ります。
また、FUJI XEROXのサイトによると、DocuWorksの内蔵OCRは活字OCR専用で、手書きのOCRには対応していません。
ということです。
ドキュワークスのOCRに関する情報はDocuWorksのOCR(文字認識)や検索の操作方法について教えて欲しい。
(http://support.fujixerox.co.jp/faq.asp?f=4292)が詳しいです。
部分的にOCR処理する
基本的にはデフォルト値で問題ありませんが、使えそうなオプションとして、OCR処理する領域の指定があります。
構造体 XDW_OCR_OPTION_V5_EXの第10要素の nAreaNum と第11要素の pAreaRectsについて、XDWAPI仕様書には次のように説明されています。
unsigned int nAreaNum;
OCR処理する領域の個数を指定する。pAreaRectsに指定された四角形の個数に一致しなければならない。0が指定された場合はページ画像の全面がOCR処理される(default)。
XDW_RECT** pAreaRects;
OCR処理する領域の座標(四角形)を指定する。四角形の個数はnAreaNumと一致しなければならない。座標はページ左上隅を原点とし右方向および下方向が正の値をとる。単位は1/100mmである。指定された領域が重なっている場合は、その部分が重複してOCR処理される。
nAreaNum に0を指定するとページ全体をOCR処理しますが、それなりに時間がかかります。
いつも決まった一部分だけをOCR処理すればいいといった場合は、OCR処理する領域を指定すれば、処理速度の点でもファイル容量の点でも効率的です。
技術的なこと
数値型配列のポインタのポインタを構造体に渡す
関数 XDW_ApplyOcrを使うにあたって、とまどった事が一つ。
構造体 XDW_OCR_OPTION_V5_EX の第11要素 XDW_RECT** pAreaRects にはOCR処理する領域の座標(四角形)をXDW_RECT構造体として指定します。
XDW_RECT構造体はDocuWorks API仕様書に定義が記載されています。
XDW_RECT構造体
XDW_RECT 構造体は、四角形の左上隅と右下隅の座標を定義する。
struct XDW_RECT {
long left; 四角形の左上隅の x 座標を指定する。
long top; 四角形の左上隅の y 座標を指定する。
long right; 四角形の右下隅の x 座標を指定する。
long bottom; 四角形の右下隅の y 座標を指定する。
};
XDW_RECT** pAreaRectsには、 アスタリスクが2つ。え?
読みかじりの知識では、アスタリスクが付くときはポインタを渡すらしいのですが、アスタリスクが2つってことは、ポインタのポインタですか?
Visual Basic 6.0 を使用して、Visual Basic と C 関数の間または Visual Basic と C++ 関数の間で配列や文字列を受け渡す方法
(http://support.microsoft.com/kb/205277/ja)の「ポインタを受け取る C 関数や C++ 関数に配列を渡す」の部分や、Visual Basic では変数のアドレスを取得するには、方法
(http://support.microsoft.com/kb/199824/ja)から分かるように、数値型配列のポインタを構造体に引き渡すには、
myXDW_OCR_OPTION_V5_EX.pAreaRects = VarPtr(myXDW_RECT(0))
のように、VarPtr関数を使って、配列の最初の要素のアドレスを渡せばいいと分かっています。
でも、ポインタのポインタって?
いろいろ試行錯誤を経て、分かったのは、
myXDW_OCR_OPTION_V5_EX.pAreaRects = VarPtr(VarPtr(myXDW_RECT(0)))
のように、変数のアドレスを返す関数 VarPtr をネストすることで解決しました。
「Visual Basic 6.0 を使用して、Visual Basic と C 関数の間または Visual Basic と C++ 関数の間で配列や文字列を受け渡す方法」には、次のように説明されています。
Visual Basic では、配列は SAFEARRAY として格納されます。SAFEARRAY は、次元数や各要素のサイズなど、配列に関する情報が含まれる構造体です。C や C++ では、配列の名前が、その配列の先頭の要素を格納したメモリ位置へのポインタになっています。
ということは、やっぱり、 数値型配列のポインタのポインタを渡すには、配列の先頭要素を VarPtr 関数でネストすればいいってことになりそうです。
これって、バグ?
サンプル中の2つのプロシージャ「ApplyOcrAll」と「ApplyOcrParts」の XDW_ApplyOcr 関数の使い方を比べていただくと分かるのですが、「ApplyOcrAll」では XDW_ApplyOcr 関数の返り値を受けていませんが、「ApplyOcrParts」では、変数 Err_XDW_ApplyOcr に返り値を受けています。(特に返り値で何か判断させるってこともしてないのですが。)
実は、「ApplyOcrParts」の様に、OCR処理する領域を指定して XDW_ApplyOcr 関数 を利用する場合、どうやら返り値を受けないと、OCR処理されないようなのです。
私の実行環境は一つしかないので、もしかするとこの環境特有のものかもしれませんし、VBA特有の現象かもしれません。
富士ゼロックスの関係者の方、もしくは識者諸兄でご指摘いただけるとうれしいです。
使えそうな気がしてきた
いろいろ試してみて、ドキュワークスのOCR処理はなかなか使えそうな気がしてきました。
日頃、いろいろな書類を複合機でドキュワークスに落としこんで、スクリプトでドキュワークス文書の自動正立と文書の結合、アノテーションの貼り付け、ファイルのリネイムと移動をしています。
まずは、この一連のスクリプトの中にOCR処理を取り込んでみようと考えています。
資料集であるとか、スクラップのような類のものならば、全文検索が可能になって、面白いものができそうです。
また、ファイル名やテキストアノテーション、(ユーザー定義)文書属性の設定にOCRの結果を利用するってこともできそうです。もちろん、OCR処理をしただけではだめで、テキスト情報を取り出す必要があるし、OCRの読み取り結果をそのまま使うわけにはいかないので、一旦インプットボックスやフォームのテキストボックスに表示させる必要があるでしょう。
経理系の作業なら、会社名の確認など誤処理防止に使うこともできそうです。
最近のコメント